
In the next few posts, I shall be discussing recent topics of study that, to me at least, have been very intruiging. In previous posts, I have talked about Hilbert spaces. I have of late been considering the mathematics necessary to formally understand in a pure mathematical sense what a Hilbert space is. This post, like the others on this site, serves as a reference of newly learned topics that are of interest (to me, at least; such a comment is subjective, of course).
The purpose of this post is two-fold: (1.) to provide an update with what I’ve been up to; (2.) introduce some interesting mathematics that have expanded my understanding to the “size” of a set as well as operations such as differentiation and integration.
Here is a quick summary of what I plan to cover in the next few posts (to a brief extent):
- Elementary Sets and their Measure: Here I will discuss the concept of length and try extend length in greater dimensions to that of a measure of a set. Much of this topic will rely on geometric intuition.
- Lebesgue Measure: This section will dicuss the concept of Lebesgue measure and distinguish it from the elementary measure. Also brief mention will be made of measurability of sets and functions.
- General Measure: Discussion will be made of a general measure as a function as well as measurable spaces and measure spaces.
- Lebesgue Integral: This topic will introduce the concept of the Lebesgue integral as compared to the Riemann integral.
and
spaces: This section will discuss the concept of a norm as it relates to the spaces
- Proof that
Section 1: Elementary Sets and their Measure:
The question that we want to answer is this: Given an arbitrary set, how do we go about measuring it?
In order to understand the difficulties present in this question we must first consider what are called elementary sets and the elementary measure. Elementary sets are those sets which are intuitively easy to measure; that is, intervals, rectangles, and boxes. We now give the formal definition of an elementary set:
Definition. (Interval; Elementary Set) We define an interval to be a subset of the real line 
![[a,b] := \{x\in \mathbb{R}|a\leq x \leq b\} \label{(1.1)}](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+%3A%3D+%5C%7Bx%5Cin+%5Cmathbb%7BR%7D%7Ca%5Cleq+x+%5Cleq+b%5C%7D+%5Clabel%7B%281.1%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)

![(a,b] := \{x\in \mathbb{R}|a< x\leq b\} \label{(1.3)}](https://s0.wp.com/latex.php?latex=%28a%2Cb%5D+%3A%3D++%5C%7Bx%5Cin+%5Cmathbb%7BR%7D%7Ca%3C+x%5Cleq+b%5C%7D+%5Clabel%7B%281.3%29%7D&bg=ffffff&fg=333333&s=0&c=20201002)

The length of an interval ![I=[a,b]](https://s0.wp.com/latex.php?latex=I%3D%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002)





we sometimes call sets of dimension 2 or greater as “boxes.” Thus, elementary sets are those subsets of 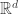
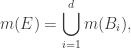
where 

What this definition is doing is the following: first it introduces the concept of an interval and establishes the well-understood concept of its length as being the difference between the two endpoints provided one is less than the other. The definition then generalizes the idea of a length to 2 and 3 dimensions and beyond. Note that in 2-dimensions the interval then becomes a rectangle in the plane. Thus, the measure of the length of an interval then becomes the measure of the area of a rectangle. Similarly, for 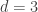

Section 2: Lebesgue Measure
In the last section, we discussed sets for which we can measure quite easily. Though ideally we would like to be able to measure more general sets; that is, sets that are more general than elementary sets. Therefore, we require a different way of measurement. Thus, we come to need the Lebesgue measure.
In order to introduce the Lebesgue measure we need to first introduce the concept of the outer measure, which we now define
Definition. (Outer Measure) We define the outer measure of a set 
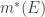

The outer measure of a set in a sense “overestimates” the size of a given set and then takes the smallest such overestimate to within a specified tolerance. Thus, it estimates the size of the given set “from the outside,” and is used in lieu of the elementary measure when we are dealing with sets that we cannot easily measure the set in a geometrically-intuitive way.
We conclude this post with the definition of the Lebesgue measure given in two forms; the first will be in terms of what we have defined so far, and the second will be defined in terms that will be covered in the next post.
Definition. (Lebesgue Measure.) We define the Lebesgue measure of the set 
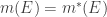
The second way of defining this is as follows:
Definition. (Lebesgue Measure V.2) The Lebesgue measure is the measure on the measureable space 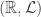

The next post will discuss measures in general, as well as measurable sets, measureable spaces, Borel sets, and
Until then, clear skies!

 be any infinite bounded set of
be any infinite bounded set of 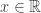 such that every open ball centered on
such that every open ball centered on  will contain at least one point in
will contain at least one point in  .
.  be a metric space with the defined metric
be a metric space with the defined metric  . Then an open cover for
. Then an open cover for  such that
such that  .
. may be of infinite cardinality.
may be of infinite cardinality.  , and let
, and let 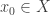 . Then
. Then 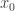 is a limit point or a cluster point of
is a limit point or a cluster point of  , of a subset
, of a subset  .
.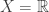 and let
and let 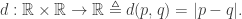 Then the open interval
Then the open interval  is not a compact set. To see why consider the set of open subsets
is not a compact set. To see why consider the set of open subsets  for
for 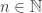 . Note that
. Note that  . However,
. However,  . In other words, (or rather in words) what this says is that if we consider all of the open sets of the form
. In other words, (or rather in words) what this says is that if we consider all of the open sets of the form 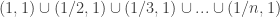 contains the interval
contains the interval  . However, note that if we take only a finite number
. However, note that if we take only a finite number  , for simplicity say
, for simplicity say 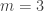 , then we have that the union
, then we have that the union  does not contain all of the points that are contained in
does not contain all of the points that are contained in  is compact if every sequence in
is compact if every sequence in  that equipped with an inner product
that equipped with an inner product  .
.  where
where  . A point
. A point  is called a limit of the sequence of points if for any
is called a limit of the sequence of points if for any  , there exists
, there exists 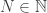 such that if
such that if 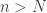 ,
,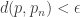 . If such a limit exists, then we say that the sequence of points
. If such a limit exists, then we say that the sequence of points  .
. 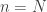 which corresponds to the point
which corresponds to the point 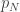 in the metric space
in the metric space  . We can regard the term
. We can regard the term  .
.  of each other in the metric space
of each other in the metric space 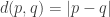 is a complete metric space. Intuitively, what this means is that given a Cauchy sequence that converges in
is a complete metric space. Intuitively, what this means is that given a Cauchy sequence that converges in  .
.  . This serves as the basis for the intuitive concept of a “space”, and our ability to ascribe a distance between to points in three-dimensional space can be described by a distance function
. This serves as the basis for the intuitive concept of a “space”, and our ability to ascribe a distance between to points in three-dimensional space can be described by a distance function  , or a metric. The underlying set
, or a metric. The underlying set  a real number
a real number  such that
such that 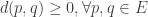
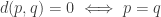
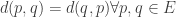

 and the metric coupled with this set is defined by
and the metric coupled with this set is defined by  . To verify that this indeed a metric space we must show that the four axioms are satisfied.
. To verify that this indeed a metric space we must show that the four axioms are satisfied.  in which
in which  is defined by
is defined by  . Then by definition of
. Then by definition of 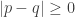 , so that axiom 1 is satisfied. Suppose now that the points in
, so that axiom 1 is satisfied. Suppose now that the points in  . Then by definition of
. Then by definition of 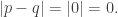 Conversely, suppose that
Conversely, suppose that  By the triangle inequality we have that
By the triangle inequality we have that 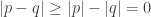 This implies that
This implies that 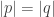 . Thus, condition (2.) is satisfied and hence the distance between two points in
. Thus, condition (2.) is satisfied and hence the distance between two points in  . By virtue of the definition of the absolute value, we can say that
. By virtue of the definition of the absolute value, we can say that 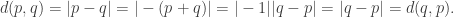
 , then the distance function between the points
, then the distance function between the points  becomes
becomes 
 ,
,


 -dimensional differentiable manifold and provide some remarks on the definitions presented.
-dimensional differentiable manifold and provide some remarks on the definitions presented.  be a set, and let
be a set, and let  be a collection of subsets of
be a collection of subsets of  ;
; where
where  are open in
are open in  .
. , in which the abscissa is the set and the ordinate is the topology, is referred to as a topological space.
, in which the abscissa is the set and the ordinate is the topology, is referred to as a topological space.  is open in the topology. Additionally, given the subset
is open in the topology. Additionally, given the subset  ; (Interior)
; (Interior)  ; and (Boundary)
; and (Boundary) 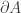 .
.  denote an open set. Then let
denote an open set. Then let  such that
such that  there exists neighborhoods
there exists neighborhoods  , of
, of  , respectively, for which
, respectively, for which  .
.  be two topological spaces. We can define a function
be two topological spaces. We can define a function  that maps the elements of a topological space
that maps the elements of a topological space  . We can now define the concept of a homeomorphism:
. We can now define the concept of a homeomorphism:  . Also, let
. Also, let  be a continuous bijective mapping. Then we say that
be a continuous bijective mapping. Then we say that  is a homeomorphism if the inverse mapping
is a homeomorphism if the inverse mapping  exists and is continuous. In the case for which this holds, we say that the topological spaces
exists and is continuous. In the case for which this holds, we say that the topological spaces  be open and assume that
be open and assume that  . We denote the partial derivative of
. We denote the partial derivative of  , where
, where  denotes a multiindex. Thus, for a function
denotes a multiindex. Thus, for a function  is said to be smooth provided its partial derivative exists and is continuous for all
is said to be smooth provided its partial derivative exists and is continuous for all  .
.  and suppose that we have a homeomorphism
and suppose that we have a homeomorphism  are both smooth.
are both smooth.  denote a Hausdorff topological space. Then
denote a Hausdorff topological space. Then  (called coordinate patches) which covers
(called coordinate patches) which covers  (called coordinate maps) the following holds:
(called coordinate maps) the following holds:  ,
,  defines a homeomorphism to
defines a homeomorphism to 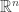 . In other words,
. In other words,  is homeomorphic to
is homeomorphic to  with coordinate maps
with coordinate maps  , respectively, said coordinate maps are compatible in the sense that
, respectively, said coordinate maps are compatible in the sense that  and forms a diffeomorphism.
and forms a diffeomorphism. 
 is a non-empty set equipped with a single binary operation
is a non-empty set equipped with a single binary operation  that satisfies the following four axioms:
that satisfies the following four axioms: ,
,  ;
; ,
,  ;
;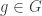 , there exists an element
, there exists an element 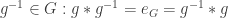 ;
; such that
such that 
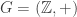 (we’ll discuss what this notation means later on in the post). Let
(we’ll discuss what this notation means later on in the post). Let 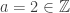 and let
and let  . We can add these two integers to get another integer, call it
. We can add these two integers to get another integer, call it  . This is what we mean by a binary operation.
. This is what we mean by a binary operation. , if
, if  is also in the set, then we say that the set is closed under the operation
is also in the set, then we say that the set is closed under the operation  . Statement 2 says that given any three elements in the set, the order in which the operation is performed, as dictated by the parentheses, is immaterial. This statement ensures that the elements of the set are associative. To clarify this a bit more, consider the following sum in
. Statement 2 says that given any three elements in the set, the order in which the operation is performed, as dictated by the parentheses, is immaterial. This statement ensures that the elements of the set are associative. To clarify this a bit more, consider the following sum in  :
:
 . For multiplication, the inverse element is the multiplicative inverse, in which case we have that for every element
. For multiplication, the inverse element is the multiplicative inverse, in which case we have that for every element  . In the definition, I was careful to include both the right and left inverse. The reason for this is not all sets of elements commute, that is it is not always true that
. In the definition, I was careful to include both the right and left inverse. The reason for this is not all sets of elements commute, that is it is not always true that  . As an example, let
. As an example, let  be the set of all
be the set of all  matrices whose determinant is non-zero. Matrices are known to non-commutative, and so
matrices whose determinant is non-zero. Matrices are known to non-commutative, and so  . If it is true that every element in the group commutes, then
. If it is true that every element in the group commutes, then  . For addition, the identity element is
. For addition, the identity element is  , since given any element of
, since given any element of 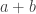 , and in multplicative notation
, and in multplicative notation 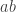 , depending on the operation involved. If all four of these axioms, as we call them, are satisfied, then the set is a group under the prescribed operation.
, depending on the operation involved. If all four of these axioms, as we call them, are satisfied, then the set is a group under the prescribed operation. , and the complex numbers
, and the complex numbers  to name a few. We denote the structure by stating what set we are considering, followed by a the binary operation, written as
to name a few. We denote the structure by stating what set we are considering, followed by a the binary operation, written as  .
. in detail and I will show how to prove that the reals and integers are groups under addition and that the complex numbers are a group under complex multiplication.
in detail and I will show how to prove that the reals and integers are groups under addition and that the complex numbers are a group under complex multiplication.

 oscillators and
oscillators and  energy units. Recall that the equation to find the entropy is the following
energy units. Recall that the equation to find the entropy is the following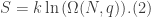


 , we may further simplify Eq.(4) such that we arrive at the expression for the entropy of an Einstein solid:
, we may further simplify Eq.(4) such that we arrive at the expression for the entropy of an Einstein solid:
 from Stirling’s approximation owing to the fact that if
from Stirling’s approximation owing to the fact that if 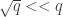 and
and  . Hence, it follows that
. Hence, it follows that 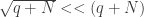 . So we see that the aforementioned factor is of no consequence provided that
. So we see that the aforementioned factor is of no consequence provided that 
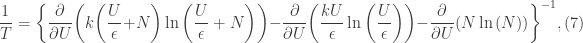
 . Differentiating and simplifying yields,
. Differentiating and simplifying yields,
 of an Einstein solid
of an Einstein solid

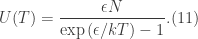


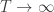 , the heat capacity
, the heat capacity  . Recall that the Taylor series expansion for the exponential function
. Recall that the Taylor series expansion for the exponential function 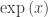 is given by
is given by
 . Then we have the approximate relation
. Then we have the approximate relation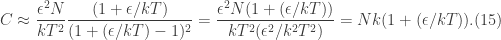

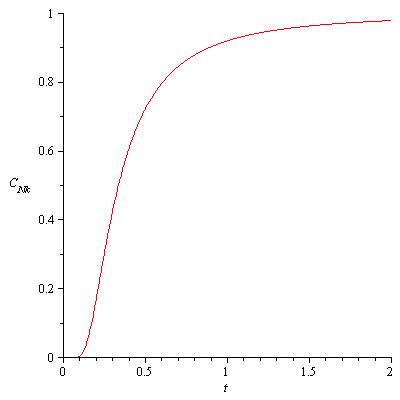
 , there appears to be a dramatic increase in the heat capacity in the dimensionless quantity
, there appears to be a dramatic increase in the heat capacity in the dimensionless quantity  . If the heat capacity
. If the heat capacity  is graphed as a function of temperature
is graphed as a function of temperature 
 is invariant with respect to Lorentz transformations. This is a pretty standard problem in most GR textbooks and in fact in some introductory books on SR.
is invariant with respect to Lorentz transformations. This is a pretty standard problem in most GR textbooks and in fact in some introductory books on SR. , there exists points whose difference relative to
, there exists points whose difference relative to  .
. -dimensional hypersphere whose surface area is given by
-dimensional hypersphere whose surface area is given by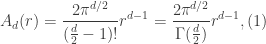
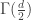 is the gamma function given by
is the gamma function given by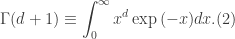

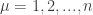 . By the method used in a previous section of the aforementioned text, we may write
. By the method used in a previous section of the aforementioned text, we may write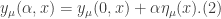
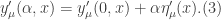
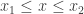 , and introducing a variational parameter
, and introducing a variational parameter 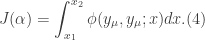


 with respect to
with respect to 
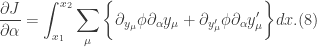





 . Since
. Since  for any
for any 